
Dgraph v21.12: Zion - The Last City Standing
We are excited to announce Dgraph v21.12 Zion release. Zion release has MAJOR performance optimizations, ...
Learn more

We have been taught, conditioned, trained to use SQL all our lives as engineers. It was there in schools, there when we went to college. It was being used at the company that we joined. It was such a common interview question that it no longer is. We don’t have just one, but an array of SQL databases to choose from. MySQL was released 22 years ago, in 1995 (youngest engineer at Dgraph was born the same year). PostgreSQL was released one year later. In contrast, MariaDB was released in 2009.
What’s amazing about SQL is its sheer simplicity. Select something where something, order by something, limit by some number. This query probably represents most DB queries run on the planet. You can achieve the same thing with a single bash command over CSV files. I joke that SQL DBs are a sort of glorified CSV file servers.
But, that’s also where lies its weakness. Its sheer simplicity. Because SQL does fewer things, application developers need to write more logic.
Dgraph does joins. Being a graph database, join is a first-class citizen in Dgraph. It’s optimized for expanding, intersecting and combining results from multiple entity types very fast. In fact, the internal mechanisms are exactly how search engines work.
Dgraph does recursions. Recursion is essentially an edge traversal. Traversing edges is very integral to Dgraph. Expanding out from a node is an O(1) time complexity operation, a look up in hash map, or a single read from disk.
Dgraph supports flexible schema. Dgraph separates storage layer from schema
layer. A developer can choose how much schema enforcement they want. Modifying
data types do not require data rewrite; and because (the equivalent of)
tables are sparse in a graph database, one does not need to fit everything
into predefined columns, or deal with NULLs.
To put something concrete up for discussion, we’ll see how data gets arranged in SQL and compare that with how it would be arranged in Dgraph. Folks at Stack Exchange generously provide dumps of their data, and the schema that they use run the site over SQL.
We’ll pick the schema that they use to store and serve the data that millions of developers browse through every day, and compare that against how it would be if Dgraph were the underlying database instead of SQL.
Let’s start with the User schema, and see how SQL would compare with Dgraph.
User
| SQL | Dgraph |
|---|---|
| Reputation | Reputation |
| CreationDate | CreationDate |
| DisplayName | DisplayName |
| LastAccessDate | LastAccessDate |
| Location | Location |
| AboutMe | AboutMe |
| Age | Age |
| Views | Views |
| UpVotes | |
| DownVotes |
Here we have user’s reputation, creation date, display name, last access date, location, about, age (not date of birth?) and views (not tracking every single page access, just a counter). All those are base data, i.e. new and unique data that we must store.
Then, the table has counts of upvotes and downvotes. But, those are being stored
elsewhere in Vote table. These fields here are pre-computed counts to avoid
doing joins with Vote table when querying for a user.
Dgraph doesn’t need to store these. It can do counts and sorts on them via queries efficiently.
Let’s look at the Versioning and Post table, where most of the action happens. These tables store the questions, answers, tags, ownership, and authorship information.
Versioning
| SQL | Dgraph |
|---|---|
| TypeId | Type |
| PostId | Post (point to Post) |
| CreationDate | CreationDate |
| Author | Author |
| Text | Text |
Post
| SQL | Dgraph |
|---|---|
| TypeId | Type |
| ParentId | Has.Answer |
| AcceptedAnswerId | Chosen.Answer |
| Title (duplicate of versioning) | Title (point to Version) |
| Body (duplicate of versioning) | Body (point to Version) |
| Tags (duplicate of versioning) | Tags (point to Version) |
| OwnerUserId | Owner (point to User) |
| Score | Score |
| LastEditorUserId | |
| LastEditDate | |
| LastActivityDate | |
| CommentCount | |
| AnswerCount | |
| FavoriteCount | |
| CreationDate |
Version table is pretty straightforward. It stores type, post id, creation date, author, and text. Instead of storing ids, Dgraph creates a relationship from Version to Post.
Post table is the interesting one, and shows how much data duplication needed to happen to avoid joins. We have the text of title, body, and tags from the latest version stored in this table. In fact, the latest version isn’t even written. Version only gets created when a user modifies the title, body or tags. And because of this requirement to proxy for Version table, Post table stores last editor, last edit date, which would become the author and creation date respectively when moved to Version table.
All these fields are unnecessary in Dgraph. Dgraph can directly store an edge to the Version node which contains the text of title and body. We chose to store tags differently. For each tag, we create a node and create an edge between the post and the tag. This allows us to run aggregations over tags, and find the most popular and most related tags easily.
Then, we have pre-computed counts of comments, answers, and favorites. Dgraph can generate all this at query time efficiently; using them to do sorting as well. So, they don’t need to be pre-computed in Dgraph.
CreationDate and LastActivityDate are both redundant information, that can be deduced by doing recursion. They form good candidates for optimization later on, but are not needed and hence are not present in Dgraph.
Comment, Vote
| SQL | Dgraph |
|---|---|
| PostId (Vote/Comment -> Post) | (New edge from Post -> Vote/Comment) |
| Timestamp | Timestamp |
| Author | Author |
| VoteType (for Vote) | Score (for both Vote and Comment) |
| Text (for Comment) | Text (for Comment) |
Finally, we have the comment and vote tables. Because SQL doesn’t store lists of things in a single row, you must create another table and point it back to the original row. A post contains comments. But in SQL, it’s the reverse. A comment table row points to the post. This is such a common hack that it’s no longer considered one.
In Dgraph, a Post has an edge to the vote or comment, not the other way round.
This is how the final Dgraph schema looks. It’s a lot simpler than SQL.
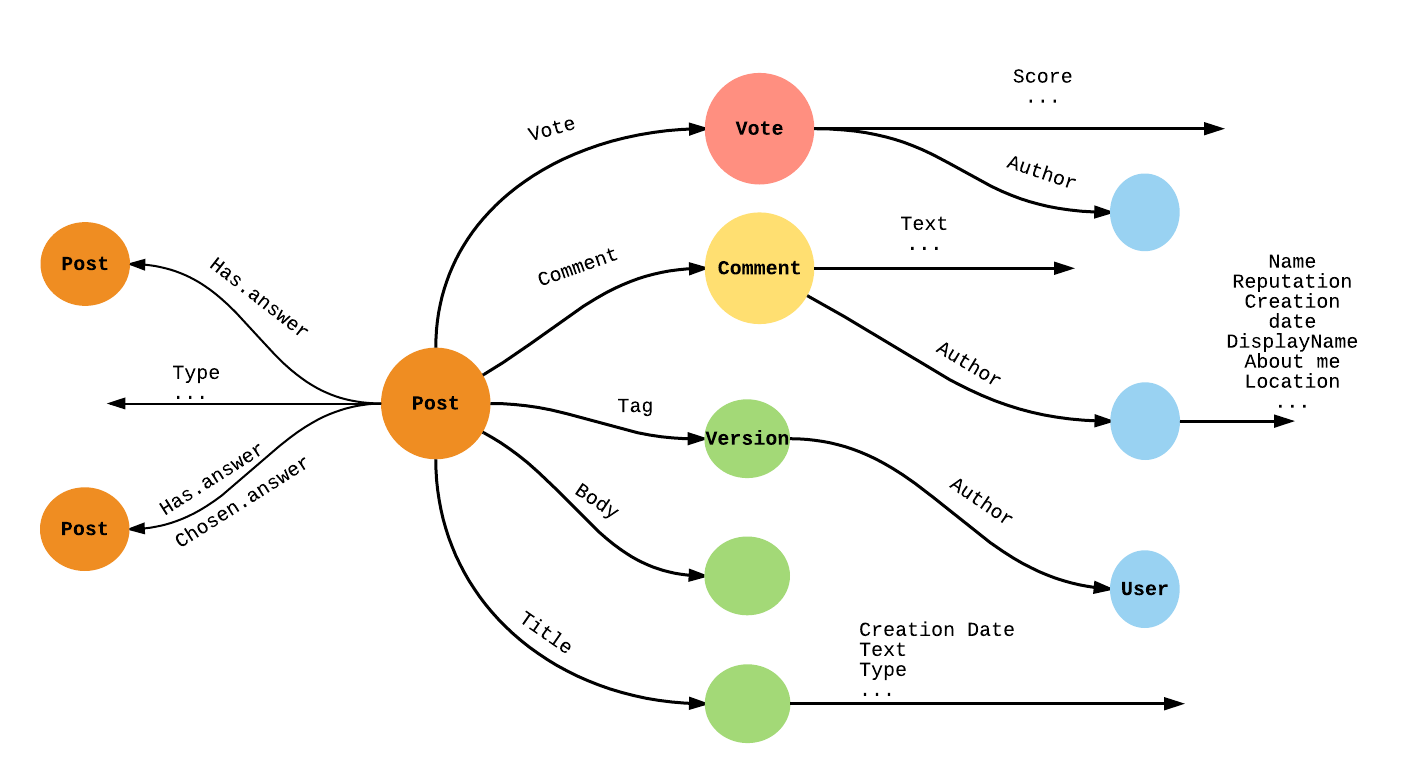
In fact, SQL schema complexity increases rapidly as the relationships among data increase. Each relationship would inadvertently require joins, which would then need to be avoided by duplicating more information across tables. All this adds a significant amount of application logic to deal with.
Conversely, in a graph database like Dgraph, schema is a pretty close representation of your mind map.
In the previous section, we saw that Dgraph schema is a lot simpler than the equivalent SQL schema. In this section, we’ll see why that is the case, and how Dgraph’s GraphQL inspired query language makes it easy to render various Stack Overflow (referred to as SO) components.
Disclaimer: While reading the queries, note that these queries are just our approximations of how SO works. We don’t work there, and thence, certain things like ranking formulas are just put together to represent the power of the query language. It’s not what SO uses.
Let’s start with the home page. We want to render 100 questions, and all the associated meta information that SO shows.
Warning
Query syntax and features has changed in v1.0 release. For the latest syntax and features, visit link to docs.
Question Div
This is the corresponding query fragment to retrieve the data to render one question div.

_uid_ # Unique identifier
UpvoteCount: count(Upvote) # Counts the number of Upvote edges.
DownvoteCount: count(Downvote) # Counts the number of Downvote edges.
AnswerCount: count(Has.Answer) # Counts the number of Answer edges.
ViewCount # Retrieves the ViewCount property stored.
Title { # Title points to Version node.
Text # Retrieves the text of the title.
}
Owner { # Owner of the question, points to the User node.
DisplayName # User's display name, reputation, and identifier.
Reputation
_uid_
}
Tag { # Points to multiple Tag nodes.
TagName: Tag.Text # Retrieves the text of the tag.
}
Has.Answer(orderdesc: Timestamp, first: 1) { # Picks the most recent answer.
Timestamp # Retrieves Timestamp of the Answer.
Owner { # Retrieves the Owner of that Answer.
DisplayName # Retrieves display name, reputation, and identifier.
Reputation
_uid_
}
}
Now that we have the question fragment let’s see how to retrieve a list of questions depending upon the various tabs that SO shows.
Latest 100 questions
# All nodes of type question, in descending order by Timestamp, limit by 100.
questions(func: eq(Type, "Question"), orderdesc: Timestamp, first: 100) {
${questionFragment}
}
Top 100 hot questions
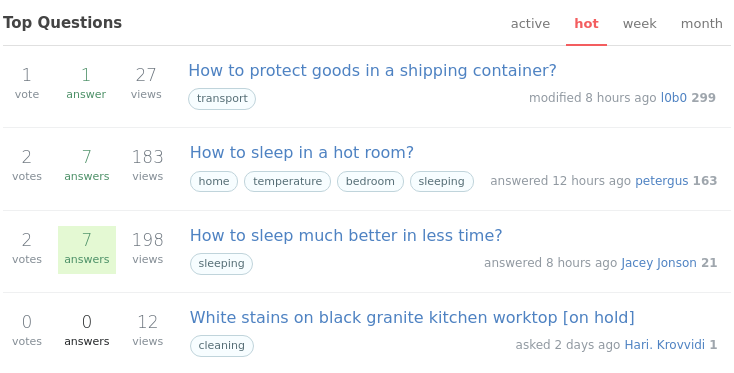
# Get the latest 1000 questions.
var(func: eq(Type, "Question"), orderdesc: Timestamp, first: 1000) {
Has.Answer { # Get their answers
uv as count(Upvote) # Count the Upvote edges.
dv as count(Downvote) # Count the number of Downvote edges.
}
ac as count(Has.Answer) # Count the number of Answers.
cc as count(Comment) # Count the number of Comments.
uv1 as sum(var(uv)) # Sum up all Upvotes across all Answers.
dv1 as sum(var(dv)) # Sum up all Downvotes across all Answers.
# Put together a rough formula to calculate a final score per question.
score as math(0.7 + ac * 0.2 + (uv1 - dv1) * 0.4 + (cc) * 0.4)
}
# Order the 1000 questions in descending order of score, pick the first 100.
questions(id: var(score), orderdesc: var(score), first: 100) {
${questionFragment}
}
Top Tags

To get the most frequently used tags, we can run this query.
t as var(func: eq(Type, "Tag")) { # Retrieve all tags. Assign it to variable t.
c as count(~Tag) # For each tag, count the number of incoming edges.
# This gives us the number of times each tag is used.
}
# For all tags in t, order them by count c and pick the first 10.
# This gives us the ten most popular tags.
topTags(id: var(t), orderdesc: var(c), first: 10) {
_uid_
TagName: Tag.Text # Retrieve the text of the tag.
QuestionCount: var(c) # Reusing variable c, retrieve the number of times tag is used.
# Note that only questions have tags. Hence we use QuestionCount alias.
}
Depending upon the number of tags, this query might be a tad slow. The most popular tags don’t change that often. So, this is a good candidate for caching in application. But, even so, the amount of application code that needs to go in to generate the list of most popular tags is very little (run the query, cache the results).
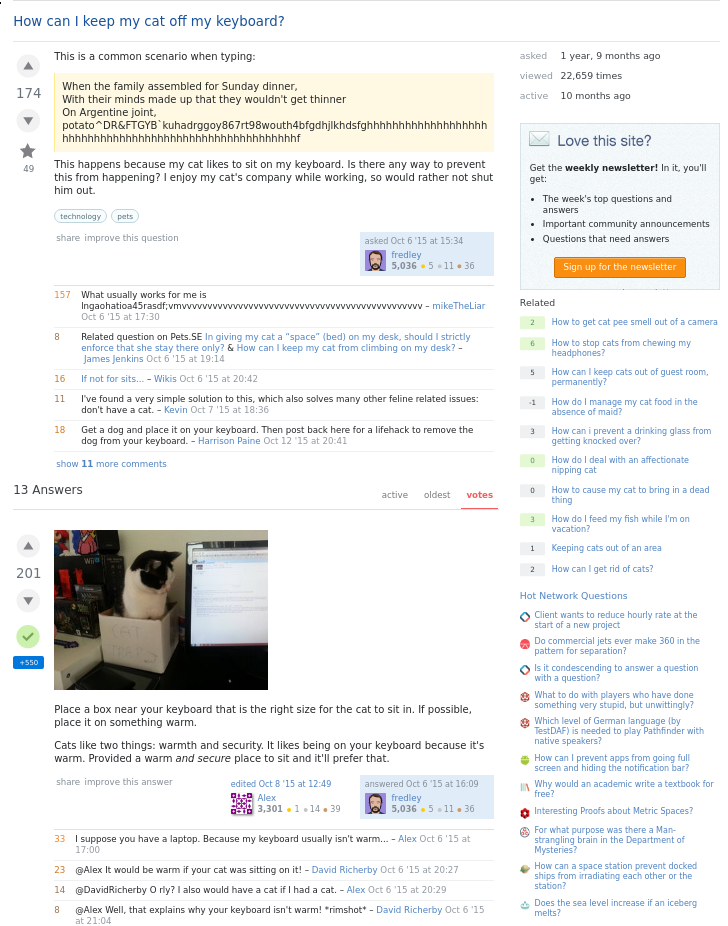
Now let’s see how to render the question page. This is one complex page, with many components, touching almost all the tables in SQL. We’ll see how we can get all the information in a single query to Dgraph.
Before we dig into the question query, let’s create a bunch of reusable fragments.
Version Fragment
Author { # Retrieve Author node.
DisplayName # Retrieve their display name, reputation, and identifier.
Reputation
_uid_
}
Type # Retrieve type, text and timestamp of Version.
Text
Timestamp
Comment Fragment
_uid_
Author { # Retrive Author node.
_uid_ # Retrieve their display name and identifier.
DisplayName
}
Text # Retrieve Text, Score and Timestamp of Comment (no versioning here).
Score
Timestamp
Answer Fragment
# Answer is represented as a Post node.
_uid_
Body { # Retieve body Version node.
Text # Retrieve text of Body.
}
# This is used for "answered x time ago."
Owner { # Retrieve owner User node.
DisplayName # Retrieve their display name, reputation, and identifier.
Reputation
_uid_
}
Timestamp # Retrieve timestamp and type of Post.
Type
UpvoteCount: count(Upvote) # Count the number of Upvote and Downvote edges.
DownvoteCount: count(Downvote)
# Post edge takes us from Version -> Post. ~Post is the reverse of that, taking us from Post -> Version. We order the Version nodes in desc order of Timestamp and pick the first 1. In other words, pick the latest Version of Answer.
# This is used for "edited x time ago."
History: ~Post(orderdesc: Timestamp, first: 1) {
${VersionFragment}
}
# These are comments on answer. Question also have comments which are retrieved in the query below.
Comment { # Get the Comment nodes.
${CommentFragment} # Retrieve further details per Comment using fragment above.
}
Question
{
var (id: ${questionUID}) { # Retrieve the question node.
Has.Answer { # Retrieve the answers.
uv as count(Upvote) # Count the number of Upvote and Downvote edges.
dv as count(Downvote)
answer_score as math(uv - dv) # Calculate an score per answer based on votes.
}
}
question(id: ${questionUID}) { # Retrieve the question node.
_uid_
Title { # Retrieve the title Version node.
Text # Retrieve the text of the title.
}
Body { # Retrieve the body Version node.
Text # Retrieve the text of the body.
}
Owner { # Retrieve the owner of the question.
DisplayName # Retrieve their display name, reputation, and identifier.
Reputation
_uid_
}
ViewCount # Retrieve some question properties.
Timestamp
Type
UpvoteCount: count(Upvote) # Count the number of Upvote and Downvote edges on question.
DownvoteCount: count(Downvote)
questionTags as Tag { # Retrieve the question Tag nodes.
TagName: Tag.Text # Retrieve their text.
}
AnswerCount: count(Has.Answer) # Count the number of answers.
Has.Answer(orderdesc: var(answer_score)) { # Retrieve the Answer nodes, and order them by the score calculated above.
${AnswerFragment} # Retrieve answer details using fragment above.
}
Comment { # Retrieve Comment nodes.
${CommentFragment} # Retrieve comment details using fragment above.
}
History: ~Post(orderdesc: Timestamp, first: 1) { # Just like in Answer, retrieve the latest Version of question.
${VersionFragment} # Retrieve Version details using fragment above.
}
}
# In the following query block, we use the tags of this question, to get related questions, and some minimal details about them; essentially title and vote counts.
tags(id: var(questionTags)) {
relatedQuestions: ~Tag(first: 10) {
_uid_
Title {
Text
}
UpvoteCount: count(Upvote)
DownvoteCount: count(Downvote)
}
}
}
If the query above looks complex, don’t worry about it. Just read the comments, and get a sense for how we retrieve each piece of data that we need to render on the page. SO question page as mentioned before is pretty complex requiring recursions to retrieve all details of questions, comments, votes, owner, last editor. Similarly, we need answers, their comments, votes, owner, last editor. On top of that, we can sort the answers displayed by a score generated from vote counts. We can even limit the number of comments displayed if required.
With SQL DB, all of this logic would have needed to be baked into the application. But, with Dgraph, the query language is so powerful that it can all be generated right within the database: doing recursions, computing counts, putting them to generate scores and then sort by these scores. This cuts down heavily on the application code, letting a developer focus on the feature set and the best way to render the data. And that’s powerful!
Full Text Search
Dgraph also supports regular expression and full-text search in many languages.
You can create an index on string edges, to achieve this. In this case, we
created a full-text index on the Text edge.
Text: string @index(fulltext) . line from schema.txt.
{
var(func: anyoftext(Text, "${searchQuery}")) @cascade {
# All Version nodes which have any of the text in search query.
p as Post { # Retrieve their Post, assign it to variable p.
# Pick the latest Version of the Post and check that it does have the search query. This is a bit of a shuffle and can be avoided by having a direct link from Post to its latest version.
~Post(orderdesc: Timestamp, first: 1) @filter(anyoftext(Text, "${searchQuery}"))
}
}
# Pick the first 25 such posts.
posts(id: var(p), first: 25) {
_uid_
Type
question: ~Has.Answer { # If this post is an answer, retrieve the question by traversing the Has.Answer edge in reverse.
_uid_
Title {
Text
}
}
Title { # Title Version would be present if this Post if Question.
Text
}
Body { # Body Version would be present if this Post is Answer.
Text
}
# The rest of the fields are as explained before, and are from the perspective of the question Post node.
Owner {
DisplayName
Reputation
_uid_
}
Tag {
TagName: Tag.Text
}
Chosen.Answer {
Owner {
DisplayName
Reputation
_uid_
}
Timestamp
}
UpvoteCount: count(Upvote)
DownvoteCount: count(Downvote)
AnswerCount: count(Has.Answer)
ViewCount
Timestamp
}
}
In this post, we showed you how a SQL schema compares against the equivalent schema in Dgraph, basing our analysis on Stack Overflow data. We then picked pages from Stack Overflow and showed you queries to retrieve all the data necessary to render those pages.
As you can see, Dgraph schema is significantly simpler than SQL, utilizing zero or little schema hacks, pre-computation or duplication of data. Also, Dgraph query language is way more powerful than SQL, handling most of the complexity of recursive data retrieval, ranking and sorting within the database, allowing the application to focus solely on the feature set and rendering of data.
Dgraph being a graph database provides sparsely populated fields and easy schema manipulation, which allows developers to modify data types as they iterate over their application, removing the need to do complex upgrades of the entire system.
Not only that, Dgraph makes it a lot faster for developers to iterate. Modifying Dgraph queries is a lot cheaper operation for a developer, than modifying the backend code; and Dgraph provides a nice UI to allow for this.
Finally, Dgraph supports regular expressions, term matching, full-text search and equality matching for string types. All Dgraph edges are unidirectional, but Dgraph allows you to specify creating reverses automatically, to aid in data retrieval. It also supports indexing various other data types, like int, float, datetime, etc.; very useful to build applications today.
Overall, this post sheds light on why we think a graph database like Dgraph is a better choice for developers today. It simplifies the data model, significantly cuts down on the backend code, and allows faster iteration.
All the data generation, querying and rendering code is located at Dgraph’s Graph Overflow repository. Dgraph query language spec is located here. Graph overflow site is still a work in progress, and we’ll put it up at dgraph.io soon.
